Para utilizar GOLD Parser en Python, lo primero que a realizar es instalar pygold, el programa encargado de instalar las librerías necesarias para poder enlazar los archivos de GOLD Parser a Python.
Se puede descargar desde aquí: http://pygold.sourceforge.net/. El archivo de instalación a la fecha es la versión 0.9.2: pygold-0.9.2.win32.exe.
Una vez instalado, vamos a GOLD Parser para generar los archivos necesarios.
Pasos en GOLD Parse
Con la gramática ya realizada, procedemos a generar el archivo .cgt:

Recordar donde se guarda el archivo .cgt, ya que nos servirá posteriormente.
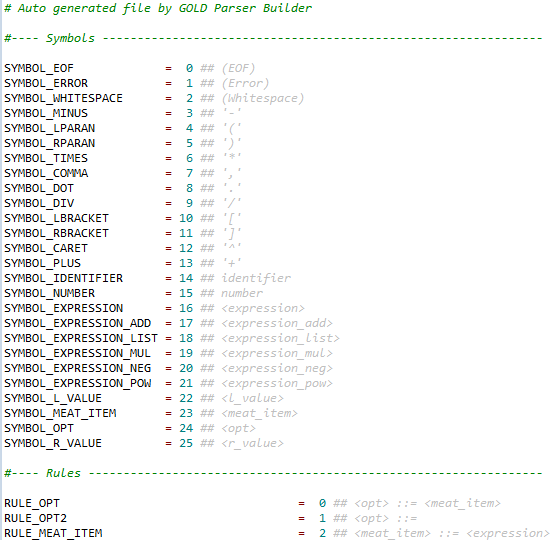
Para generar el archivo compatible con Python seleccionamos la opción: “Python – Constants Only” y luego hacemos clic en “Create”, donde se nos pedirá donde guardar el archivo que contendrá la identificación de los símbolos y reglas de la gramática. Se deberá guardar ese archivo en la misma ruta de nuestro archivo de python.
Pasos en Python
Ahora en nuestro archivo de python se hacen las siguientes modificaciones para poder implementar lo realizado en GOLD Parser:

Se agrega el anterior código al principio del archivo. Este código manda a llamar los módulos necesarios para el parser, así como importa “pygold” para poderlos utilizar.
El archivo con las identificaciones de la gramática se importa con la línea: “from archivoGenerado import *”, donde “archivoGenerado” es el nombre que se le había puesto al archivo con los símbolos de la gramática.
Se definen las funciones “onToken” y “onReduction” con los parámetros indicados:
def onToken(parser, token):
def onReduction(parser, reduction, tokens):
Dentro de dichas funciones se implementan las acciones semánticas de acuerdo al token o reducción realizada según los identificadores en el archivo generado.
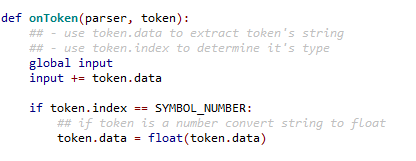
Como en el ejemplo de la imagen, para la función “onToken”, el identificador del token se guarda en:
token.index
Y el valor del token en:
token.data
Con lo anterior, se puede realizar la comparación necesaria para efectuar acciones de acuerdo al token analizado.

Para la función “onReduction”, el identificador de la producción reducida está en:
reduction.data.rule.index
Y el valor a retornar se almacena en:
reduction.data
Para acceder a los valores devueltos por los símbolos de la producción, se realiza con:
tokens[valor].data
donde “valor” es el número del símbolo de la derecha de la producción empezando de 0 de izquierda a derecha.
Con lo anterior, se puede realizar la comparación necesaria para efectuar acciones de acuerdo a la producción reducida.
Para poder utilizar lo anterior, se deberá crear una variable que implementará el parser:
p = pygold.Parser(‘archivo.cgt’, ‘utf-8’)
donde se indica la ruta del archivo .cgt creado anteriormente, y la codificación de caracteres a utilizar.
Con esa variable a disposición, se le asignan las funciones anteriores:
p.onReduction = onReduction
p.onToken = onToken
Para ingresar el texto a analizar, hay 2 formas:
· p.openFile('test.input.txt')
donde se indica la ruta de un archivo de texto a analizar
· p.openText('2+3*7/sin(cos(alfa*4)+5)')
donde se introduce directamente el texto a analizar
Para empezar el proceso, se manda a llamar la función “parse”:
result = p.parse()
Se puede guardar el valor de la última reducción realizada si al llamar a la función “parse” se le iguala una variable.
Finalmente, se cierra el archivo utilizado o el texto analizado:
p.close()
Archivo de Ejemplo:

Y así terminarían los pasos necesarios para implementar GOLD Parser en Python.
No hay comentarios:
Publicar un comentario